一篇非常深入UPMEM PIM底层实现的文章,值得深读。
问题
目前UPMEM PIM的PIM间沟通性能低,通用且高性能的Collective Communication Framework缺失。
性能低的原因有三点:
- 纠缠组的存在导致难以有效利用带宽
- 通信过程需要CPU的参与
- 通信流程为MRAM-VEC_REGISTER-CPU_MEMORY-VEC_REGISTER-MRAM
背景
纠缠组 Entangled Groups
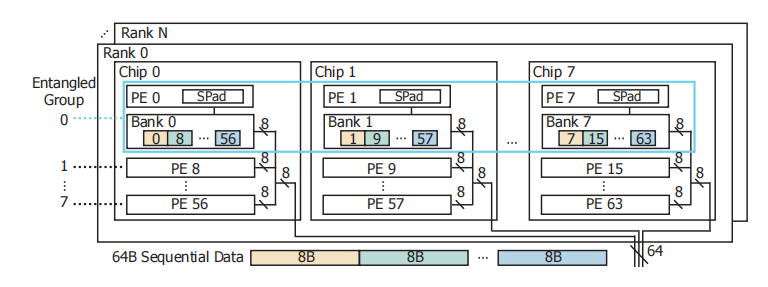
要充分利用64位的访问总线,需要同时访问一个纠缠组中的8个bank,这八个bank分别位于同一个rank的8个chip中。
域转换 Domain Transfer
CPU对PIM读写数据,是通过AVX-512指令集(基于SIMD思想的x86高级向量扩展指令集)进行的。该指令集搭配的是512位向量寄存器(通常有32个),一个CPU核心可以在一个周期内,实现一条指令对单个512位寄存器中的多个数据执行相同操作(如读、写、与另一512位寄存器的多个数据进行并行算术运算等)。
CPU和PIM对数据的布局要求不同,原来的UPMEM PIM设计默认会在读写数据时,在到达向量寄存器时进行一次“矩阵转置”,称之为域转换。
通信原语
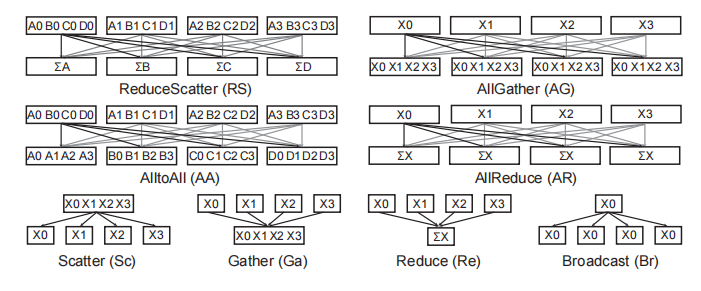
设计
设计超立方体抽象通信拓扑,支持多实例的集体通信。通过合理地生成多立方体和实际PIM单元的映射,最大程度地符合内存并行传输特性(包括bank-level、chanell-level等)。

多实例通信在超立方体架构中,可以并行地沿着边进行,且相比于树拓扑和环拓扑,有着更好的对称性,从而结点间通信更加灵活。通过在PIM端增加运算,并减少无意义的域转换(当CPU不需要进行算术运算,只是作为单纯的传输中介时,域转换没必要),减少CPU的参与
通过谨慎地排布数据,使得操作尽可能在向量寄存器中即可完成,而无需放到CPU内存中。