人工智能 (AI)
人工智能是一个广泛的领域,旨在开发能够像人类一样执行任务的系统。实现人工智能的方法包括专家系统、搜索与优化算法、机器学习等
机器学习
一些入门的文章:https://blog.csdn.net/qq_40181592/category_9106302.html。
在深度学习出来之前的机器学习方法,可以称之为传统机器学习,包括线性回归、FM、SVM支持向量机、决策树等。
FM (Factorization Machines 因子分解机)
论文:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=5694074&tag=1
blog:https://mp.weixin.qq.com/s?__biz=Mzg5NTYyMDgyNg==&mid=2247489278&idx=1&sn=f3652394955d719bf02a91ca3b179ed2&source=41#wechat_redirect
首先,说一下什么是Matrix Factorization(矩阵因子分解)?给定一个二维N*M的矩阵R,求一个N*K的矩阵W和一个K*M的矩阵V,使得WV尽可能等于R,误差定义为所有元素的误差之和(显然较大的K,训练出来的误差会更小),一般K会设置得比M和N小,从而将一个
深度学习
深度学习是机器学习的一个子领域,主要基于多层神经网络,利用大规模数据和强大的计算能力来自动学习特征并完成任务。深度学习模型一般统称为DNN模型,具体包括MLP、RNN、GNN、Transformer等。
- 多层神经网络:
https://blog.csdn.net/illikang/article/details/82019945
神经网络(NN),分为输入层、隐藏层(可选)、输出层。多层神经网络意味着隐藏层有多层。下一层的每个结点结果,由上一层的某些(也可能是全部)的结点,以及训练出来的参数(可以看作是这些边的“权重”)共同计算得到,就像神经元里的信息传递过程一样。简单的神经网络,如单层神经网络(也叫Perceptron 感知器),没有隐藏层,就算不上深度学习。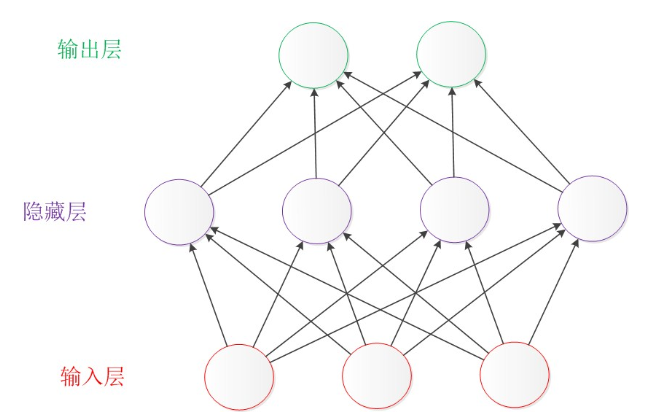
- 大规模数据:层与层之间的转换,都需要大量的参数,这些参数提高了模型的表达能力,但同时也要求大量可供训练的数据,所以数据集小的也不适合深度学习。
- 强大的计算能力:相比于传统的机器学习,多层神经网络要训练大量参数,要求的计算资源非常多,所以神经网络的第二第三次兴起都源于计算能力的提升(CPU->二层神经网络,GPU->多层神经网络->深度学习)。
- 自动学习特征:这正是深度学习与传统机器学习的不同之处https://zhuanlan.zhihu.com/p/69776750 。传统机器学习通常依赖专家来做特征工程,在建立某个模型前需要对应用领域有较深的理解,人工提炼出影响结果的特征,并用于模型中。而深度学习只需你提供一些最基本的向量化的输入(其中包含着一些最简单的特征,对应输入层的多个结点),然后在层层神经网络的推进中,特征之间不断交互,形成更高阶且非线性的特征。通过大量的训练,模型自动学习所有参数,自动考虑各种特征对于输出的“重要性”,从而形成输入和输出的复杂函数关系,颇有一种力大砖飞的美感。当然了,在这个过程中,相比于传统机器学习,自然也丧失了一些模型的可解释性。
MLP (多层感知器)
MLP应该可以算是最简单的深度学习模型了,包含一系列串联的子模块,每个子模块包括一个全连接层(FC)和一个激活函数:
全连接层,输出Y的所有元素是输入X的所有元素的加权和,可以统一用矩阵计算表示为Y=XW+b,W是权重矩阵,b是偏置向量,都是要训练的参数,每个全连接层各有各的W和b。激活函数一般就是一个非线性函数,对向量中的每个元素进行单独的非线性计算,得到一个新的向量。通过一些泰勒展开可以发现(不必深究),MLP可以捕获特征之间(输入的结点之间)的高阶和非线性交互,也就是说,可以自动学习到结果与某些高阶特征的关系,而不必人工放入某个高阶特征。