链接:https://cloud.tencent.com/developer/article/2314766
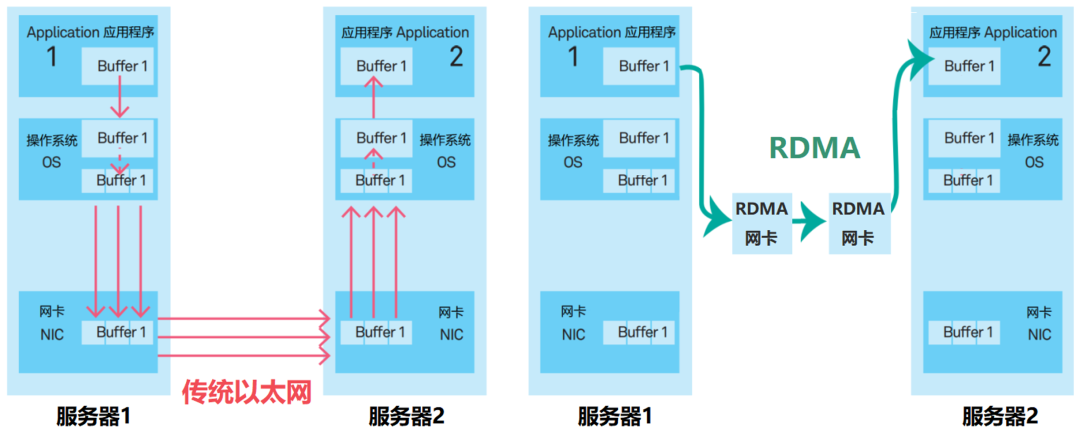
InfiniBand概念 InfiniBand(无限带宽)是一种高性能、低延迟、高带宽的网络架构,专为大规模并行计算(如高性能计算、超算、数据中心等)设计, 关注存储设备之间的连接 。它提供了一套完整的硬件和协议标准 ,支持多个通信模型,包括点对点通信、广播和组播。
核心公司:Mellanox(迈络思),后被nvidia收购。
核心技术:RDMA(远程直接内存访问)。后面以太网也支持了该技术(InfiniBand仍有许多特点,例如直接在硬件上支持了零拷贝)
直接竞争者:Ethernet(以太网)。尤其是25Gbps以上的高速以太网。二者主要区别如下,InfiniBand消灭了中间商:
InfiniBand配套硬件(NVIDIA Quantum-2 部分硬件) 英伟达收购Mellanox之后,于2021年推出了自己的第七代NVIDIA InfiniBand架构——NVIDIA Quantum-2。该架构有一系列硬件。
ConnectX系列 Adapter 属于一个pcie设备,是一个InifiniBand网络架构(当然也支持RDMA)的网卡,两个有该网卡的服务器可以互相执行RDMA。
BlueField InfiniBand DPU 属于一个pcie设备,集成了数据处理单元(不受cpu控制,可制定一些规则,处理掉某些数据包而不用再传给cpu,减轻cpu负担),可以看作一个smartnic。
OFED(OpenFabrics Enterprise Distribution) 一个专为高性能计算(HPC)、数据中心和存储网络设计的开源软件包。它的主要作用是为支持 InfiniBand 和 RDMA(远程直接内存访问)技术的硬件提供驱动程序、库和工具 ,使这些硬件能够高效运行。
这个库非常全面,所以当需要某个rdma相关的工具包时,不要急着下载,先看看这里面有没有包含。
主要功能如下:
驱动程序支持 OFED 提供了许多硬件厂商的网络设备的驱动程序(如 Mellanox、Intel 等),以正常使用对应的RDMA设备。
开发和运行 RDMA 应用程序 提供一套用户态的 RDMA API(如 libibverbs 和 librdmacm),使开发者可以编写基于 RDMA 的高效分布式应用。
性能测试与调优 提供了perftest工具包(包含 ib_read_bw、ib_write_bw、ib_send_bw等功能),用于测试和调试 InfiniBand 或 RDMA 网络的性能。ib_read_bw,客户端输入ib_read_bw 服务端地址,即可测试客户端向服务端读取数据的带宽。
perftest 5.7.0 前后版本不兼容。如果实在服务器与要测试的服务器的perftest版本兼容,也可以一台服务器测试性能,自己发自己收,因为rdma是全双工的,进出带宽不会互相影响。
设备管理支持 ibstat可用于查看当前InfiniBand设备状态。
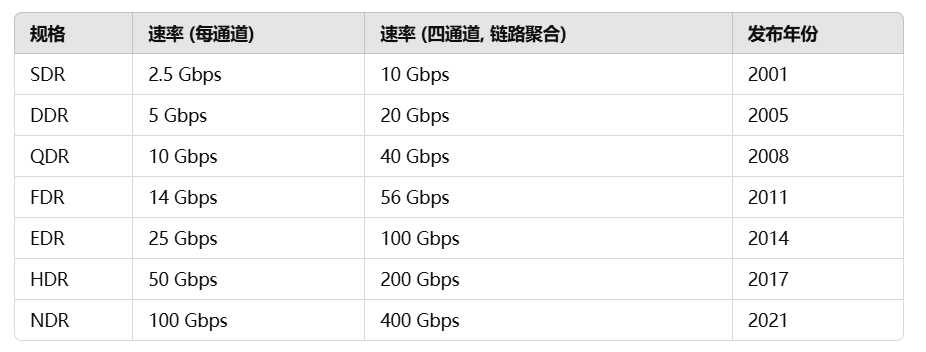
InfiniBand 带宽
输入ibstat命令,可以看到当前服务器的InfiniBand适配网卡是什么标准。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 CA 'mlx5_0' CA type: MT4119 Number of ports: 1 Firmware version: 16.35.4030 Hardware version: 0 Node GUID: 0xb8cef6030097d6fe System image GUID: 0xb8cef6030097d6fe Port 1: State: Active Physical state: LinkUp Rate: 100 # 100Gbps 对应EDR标准 Base lid: 12 LMC: 0 SM lid: 11 Capability mask: 0xa651e84a Port GUID: 0xb8cef6030097d6fe Link layer: InfiniBand # 当前是InfiniBand模式,有些也可能是以太网模式,说明此时当作以太网的网卡运行。
输入lspci | grep Mellanox找到对应InfiniBand适配网卡的设备号(如ad:00.0),再输入sudo lspci -vv -s 设备号,会有如下两个信息:
1 2 3 4 LnkCap: Port #0, Speed 8GT/s, Width x16, ASPM not supported ClockPM- Surprise- LLActRep- BwNot- ASPMOptComp+ LnkSta: Speed 8GT/s (ok), Width x8 (downgraded) TrErr- Train- SlotClk+ DLActive- BWMgmt- ABWMgmt-
LnkCap 和 LnkSta 字段显示了当前设备支持和实际使用的 PCIe 速率和通道宽度。https://blog.csdn.net/weixin_42229404/article/details/84069859。
如上面所示,实际该网卡是8通道接入pcie,导致此时pcie通道的带宽是7.877GB/s,而该EDR标准网卡的InfiniBand带宽为100Gbps(约为12.5GB/s),则rdma带宽测试是,瓶颈就会在pcie上,如果改回16通道,带宽就会是InfiniBand。